The world has officially moved on from the process of data collection to data processing and analysis.
Why? Because everyone is concerned with the outcome. They want to make informed decisions that their businesses could benefit from.
But to understand and draw your interpretations correctly, it is crucial that we understand how raw data finds shape and structure. So much so that companies have dedicated professionals who take care of their data. Data engineers were once just one of the few lesser-known but indispensable part of the picture. However, it is slowly gaining traction.
Data engineering has quickly become a dire need for organizations. In 2019, the big data and data engineering market will reach $ 90.1 B and grow at a CAGR of 50% by 2026, says Reuters in their latest report.
- Ninety-five percent of businesses have active unstructured data requirements
- More than 150 Tn GB data will need processing by end of 2025
- Big Data has been associated with an 8-10 percent increase in profit margins and 8-10 percentage drop in costs
Differences between Data Scientists and Data Engineering
If you are an outsider to the world of data science, chances are you have made the same fundamental mistake that many usually do. Technological jargon on analytics, artificial intelligence, and machine learning get thrown around a lot. They tend to hold answers to all our questions. But how does data engineering really fit in the puzzle?
Let’s take a look at this borrowed infographic from BDI.
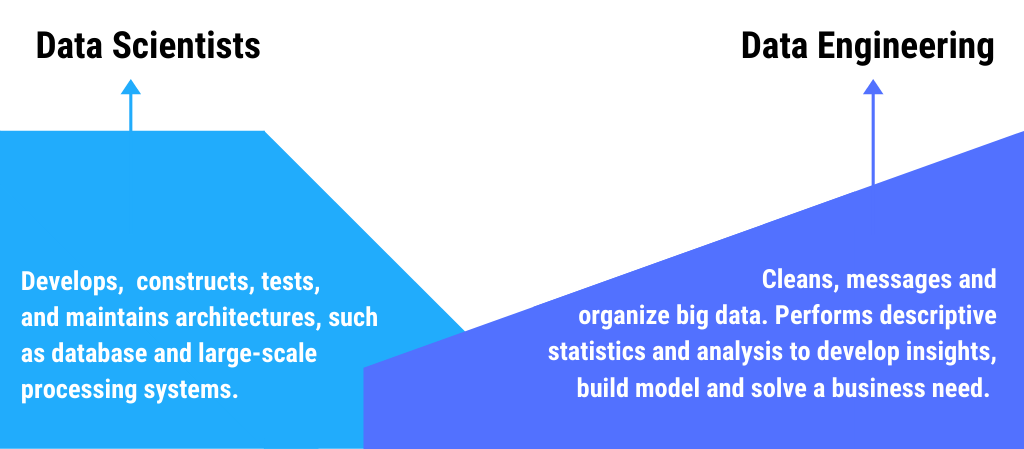
It highlights the core competencies of both the job profiles effectively.
When data is collected, it is raw, it is almost illegible. The responsibility to store and maintain the data relies on data engineering. Artificial intelligence, machine learning, and deep learning are modalities to slice and dice that data to derive what exactly is going on. Utilizing the concept of programming, raw data undergoes a set of operations termed as data engineering.
Sure, overlapping skill set has led us to believe that both the roles of synonymous. However, it is not. A data engineer deploys his knowledge of advanced programming languages like R, Python, Scala and more, alongside a thorough knowledge of data structures and algorithms to create data pipelines. Whereas, a data scientist utilizes advanced statistics on the data and translates it into usable insights.
More about data pipelines, a little later.
The bottom line is that a data engineer creates a hierarchy in the database that enables you to apply every plausible analytical approach to the data you have painstakingly collected. Whereas, a data scientist is responsible for interpreting that data in simple terms for you to make sound business decisions.
Looking for expert data engineers to help you with your data infrastructure management and data pipeline needs? Alphalogic takes immense pride in its expertise in data engineering. Book a consultation today!
Components of Data Engineering — How a Data Engineer Waves his Magic Wand
Frequently a data engineer is a quiet force, the mastermind in the equation. It is easy to assume that it is done simply by waving a magic wand. But it is not.
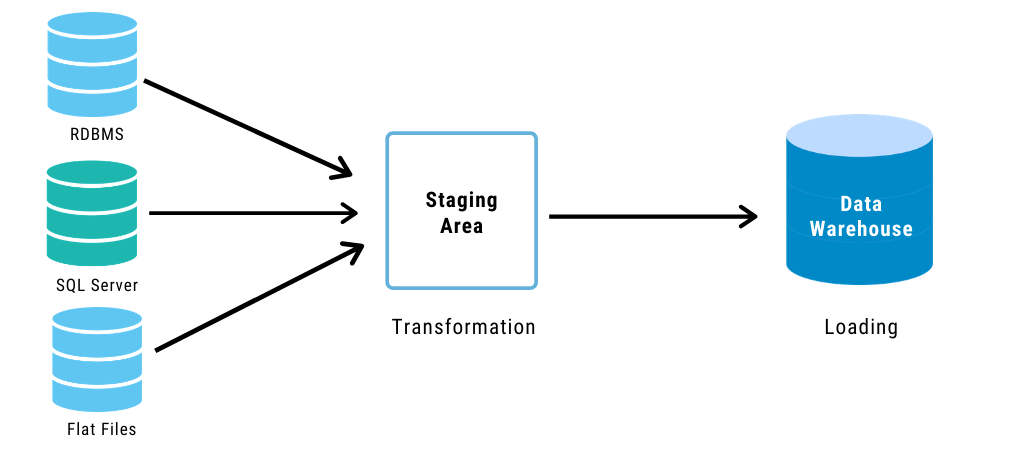
Let’s go back to the good old databases to understand the set of operations that we have been talking about relentlessly. Let’s fall back to the idea of a database.
An organization or any business has n number of types of data, including Customer Relationship Management tools, production systems and more. The existing infrastructure is dissociated, and therefore cannot be expanded to explore the full potential of the data.
Scattered, and inconsistent in different formats, the current scenario prohibits the exploration of the 360-degree picture of the business.
Who is a Data Engineer?
The data engineer is the “hands-on data professional” who will unify this data to build a system, i.e. a data warehouse. The construction and maintenance of a data warehouse (or another database) will constitute of data migration from across all these distributed systems — a role specifically undertaken by the data engineer. The data architect is responsible for designing the structure, defining each source of the data and zeroing in on a singular format.
ETL and Data Pipeline are Not Synonyms Either… and More
The data warehouse simply takes care of data storage. Now how do you handle the data? To create a big data infrastructure, the data engineer creates a data pipeline. Now, what is a data pipeline?
A data pipeline is an automated process. An organization is bound to accumulate more, and more data with every working (and non-working) day. To ensure that the handling process is effective, a data engineer employs his advanced programming skills.
The ETL methodology: Extract, Transform, and Load is not the only approach a data engineer follows. Although it is used synonymously (like data engineers and data scientists,) there is a fundamental difference between the two.
You ask, how?
Here’s how it exactly works.
In the ETL approach, the data is moved in large chunks at a scheduled time. It can be through the day, or a week doesn’t matter. Basically, data moves in batches here at regular intervals depending on the company’s size, business needs and more.
The data pipeline is often a real-time process. It may, or may not undergo a transformation. It may remain unstructured and may not be pushed to the data warehouse, or data lakes. They can be stored on cloud platforms, on open sources. That completely depends Essentially, ETL is a subset of a data pipeline.
Data pipelines are solutions for organizations in the following circumstances:
- High reliability of data and therefore, the need to maintain siloed data sources
- Dealing with highly sensitive information, such as banking information, medical records, or personal information. Such organizations need to actively maintain
- Constant generation of data from multiple sources with the utilization of this data governing everyday tasks
However, these are only a list of potential scenarios.
Types of Data Engineers
Like any other job profile, a data engineer adapts various roles. And depending on the requirements, they have to adapt. Perhaps, that is what makes data engineering such a versatile position.
Based on our work experience and observations from numerous data engineering projects we have undertaken, we have identified the following major types of data engineers:
A Data Engineer Can Be A Generalist
A data engineer, when working in small teams of three to four data science professionals carries out the entire process of executing and creating the structure of the data warehouse as well as the access and maintenance of the database. In such cases, the organization is at the budding stages. Considering that he is carrying out the end-to-end process by himself, he is pretty much a generalist at this stage.
A Data Engineer Can Be Database Focussed
A data engineer can also be database focussed. This is frequently in mid-sized companies or businesses that are actively looking at managing the data effectively. In such situations, the role of a data engineer is predominantly database focussed and governed by the ETL (Extract, Transform and Load) methodology.
A Data Engineer Can Be Pipeline Centric
In a large firm, with a fairly developed data science team, the data engineer fits in as the one responsible for the creation and execution of the data pipeline. The data architect works alongside him in developing the optimum structure whereas the data engineer is functioning with his core skill sets to optimize the algorithms, and leveraging the most out of cloud platforms.
A Data Engineer’s Toolkit
Data engineering, like any other field of data sciences, requires continuous and rigorous use of some tools.
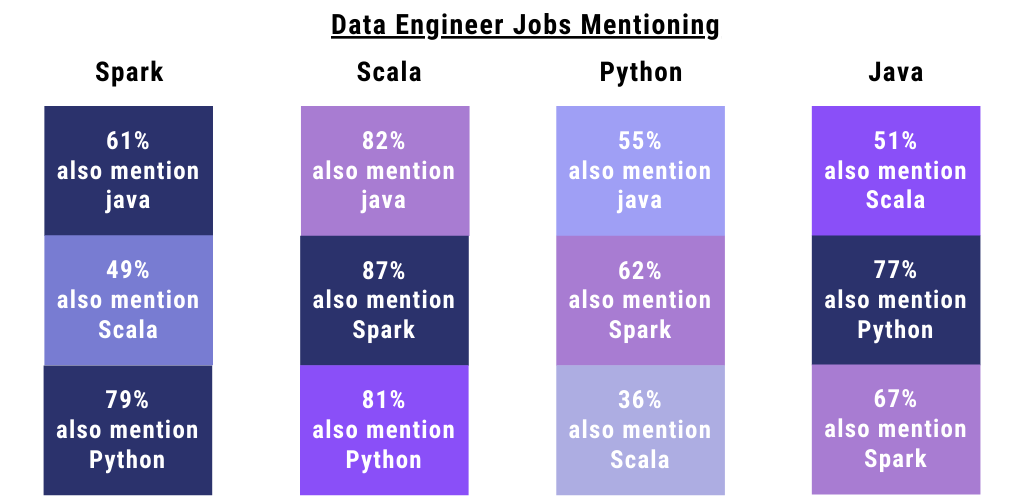
For a data engineer, it includes the following:
SQL and NoSQL
A common myth amidst data engineers is that SQL and NoSQL are outdated. Yes, there are more languages and different approaches to get things done but even Big Data has some SQL integrations.
They are typically very prominent in the front end of the data pipeline where non-technical groups can plug the holes and get directed towards insights from the data with little knowledge of programming.
Algorithms and Data Structures
Speed matters to us. Particularly, when you are assembling a platform for the non-technical group, they need the speed. Agility is a part of their job description. Algorithms are the core processes of automating the data transformation and data structures can improve the performance of the algorithms by huge margins. Need we say more?
Cloud Platforms
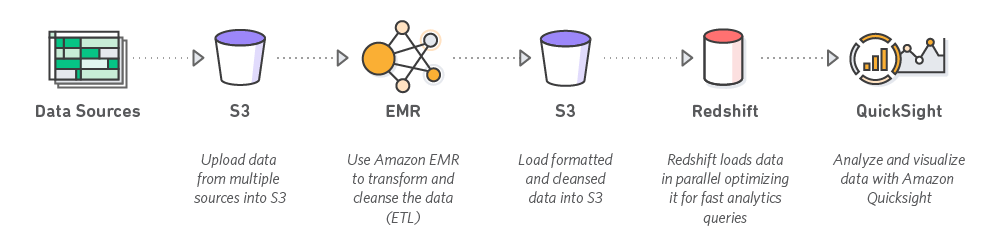
All the operations are dynamically happening on the cloud. Why? Cloud is secure. Data privacy is every organization’s biggest concern and security breaches are their worst nightmares coming alive.
Cloud platforms are the safest bet and for a data engineer, the knowledge of at least one cloud platform such as Google Cloud Platform, or, Amazon Web Services is a necessity.
Big Data Tools combined with Fundamentals of Java and Scala
This one is pretty vast. Big Data has come a long way and we have conveniently established that big data tools form the basis for the process of data transformation. Apache Hadoop, Apache Spark, Apache Cassandra, Apache Kafka, are some of the many big data platforms. They use Java and Scala extensively in addition to SQL, Python, and Julia.
Python
Python is primarily used by data engineers for statistical analysis. It is a general-purpose
language for data engineers and data scientists. In fact, Cloud Academy found Python as the most skills for data engineers.
Are you a data engineer? What are some other myths or beliefs associated with data engineering? Or maybe, there are some other skills that you feel would be beneficial to learn? Leave us a comment here.
Dhananjay (DJ) Goel is the CTO at Alphalogic, passionate about technology, startups, game of thrones and coffee. He enjoys working on challenging problems with innovative startups.