
ETL is Extract, Transform, and Load.
Even a computer science undergrad can tell you that. But the real application and the complication associated with the process can only be described by the industry professionals.
The complication was best conveyed by Ralph Kimball in The Data Warehouse Kit: The Definitive Guide to Dimensional Modelling.
“When asked about the best way to design and build the ETL system, many designers say, “Well, that depends.” It depends on the source; it depends on the limitations of the data; it depends on the scripting languages and ETL tools available; it depends on the staff’s skills, and it depends on the BI tools. But the “it depends” response is dangerous because it becomes an excuse to take an unstructured approach to develop an ETL system, which in the worst-case scenario results in an undifferentiated spaghetti-mess of tables, modules, processes, scripts, triggers, alerts, and job schedules. This “creative” design approach should not be tolerated. With the wisdom of hindsight from thousands of successful data warehouses, a set of ETL best practices has emerged. There is no reason to tolerate an unstructured approach.”
And we have been living by these words. Look, we understand that the data needs of businesses have evolved massively. Despite the changes in market trends, ETL still holds true in every essence.
Why?
Because ETL is a fundamental principle; the definitive steps of a process. You know how the water cycle has remained the same over the years — just like that! The involvement of the global rise in temperature and ozone layer depletion affects precipitation but the process remains the same in essence.
With three essential steps, ETL is a basic outline that lays the very foundation of data handling. With the evolving needs, the methodologies, approaches, and technology have witnessed groundbreaking changes. Only the how i n the equation has changed.
ETL Process Management
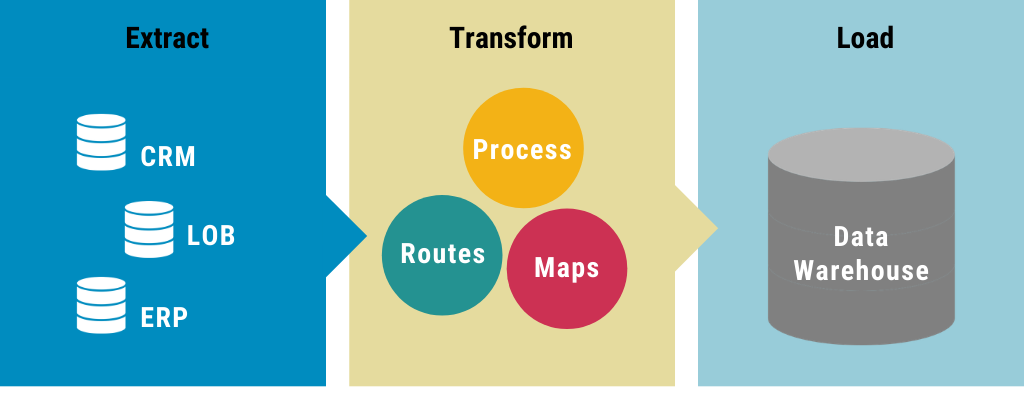
Databases can rarely be self-contained. The idea of data integration is deeply embedded in the ETL process management. In an ideal situation, you see that database management is linear with little fluctuation. In the real world, there is a stark difference — which means that the process does go haywire.
Did the above statement hit home for you? Are you looking for an experienced partner who can tend to your data handling woes? This is where we come in. Alphalogic has helped numerous clients lineate the process and eases their data handling process. Book a consultation with us here now!
If you are struggling with managing this process and conducting repairs with your ETL process management, a data engineer fits right in the groove for you. Why? Because his knowledge of advanced programming aces them all.
The Inception and Evolution of ETL
Businesses have been using data since the advent of technology. However, soon they realized that a simple flat file will not suffice. They needed complex systems that would concatenate logically and thus data integration became the need of the hour.
ETL has been an indispensable part of RDBMS since it was discovered by multiple organizations in 1970. The purpose of collecting this data has remained the same over the years — to make informed, logical business decisions powered by the data they understood and gathered first hand.
Slowly, the process grew complex and data science evolved rapidly to solve the problems associated with data handling. ETL has undergone massive changes in the implementation too.
ETL Execution through Batch Processing
This is perhaps the most primitive and the most accepted definition of the ETL approach. The data was relatively lower in size — less complex (when compared to 2019) and less prone to cyber security threats.
With batch processing, the movement of data was conducted in batches. Once in a day, once in a week, once in a month… doesn’t matter as long as the process was carried out during the time of the lowest activity.
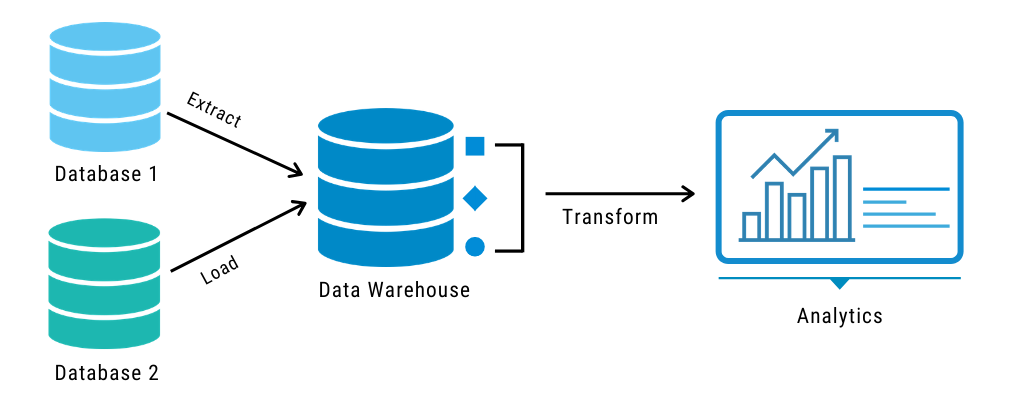
The fundamental steps in batch processing included:
- Defining reference data — The source data was defined and the outline for the set of permissible volumes in each field is drawn. For example, billing numbers had a definite syntax, product fields were restricted to a standard format of product codes, and more.
- Data Extraction — Data extraction focussed on getting the data extracted properly, in the desired format. From relational databases (RDBMS) to flat files including CSV and XML, the data was extracted to be pulled into a standardized format.
- Data Validation – Data validation, an automated process accepts, rejects (and then modifies) the data based on the accepted format. The modification batch often remained separate. The process of modification involved identifying the inconsistencies and they were scheduled to be updated on the data warehouse at a later stage.
- Data Transformation — During the data transformation stage, the focus remains on cleaning the data, preserving the data integrity by identifying any corruption resulting from the movement and more.
- Loading data to a staging database — The data from the source does not directly enter the data warehouse. It is typically moved to the staging area to initiate the generation of audit reports and data repairs if required. The rollback feature of the staging area enables faster retraction in case of any issues.
- Loading data on the data warehouse — The final step in the batch processing
approach, in this step, the data is loaded to the final tables.
This process gained traction because of efficiency and simplicity. We still use batch processing intermittently for handling repetitive tasks. Of course, we do it without overwriting or disrupting the flow.
Example: Affinity waters, the largest distributor of water on tap in the United Kingdom actively uses batch processing to manage vast amounts of data. They also leverage the benefits of stream processing. Like most firms that have gotten an upgrade, batch processing is often clubbed with stream processing for optimizing their data strategy.
ETL Execution through Stream Processing
Businesses like e-commerce websites generate huge amounts of data. Their day-to-day tasks revolve around real-time processing. Now, taking a huge leap from batch processing where businesses rely on a short turn around time, ETL saw the rise of stream processing.
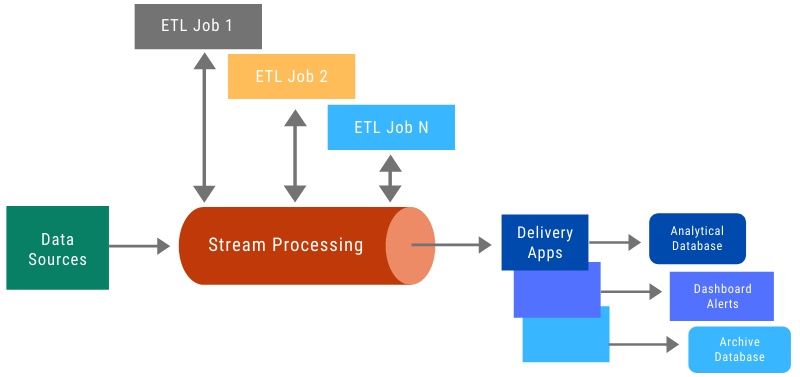
The data flow is continuous and actions are triggered simultaneously. From Apache Kafka to Apache Flink, there are multiple tools to accomplish stream processing via ETL.
The process was best described by Shriya Arora, Senior Engineer, Data Engineering and Analytics (DEA) Netflix through “Personalizing Netflix with Streaming Datasets” at QCon New York 2017.
The process was best explained in this piece. He writes and we quote,
“At a high level, microservice application instances emit user and system-driven data events that are collected within the Netflix Keystone data pipeline — a petabyte-scale real-time event streaming-processing system for business and product analytics. Traditional batch data processing is conducted by storing this data within a Hadoop Distributed File System (HDFS) running on the Amazon S3 object storage service and processing with Apache Spark, Pig, Hive, or Hadoop.“
ETL Execution through Data Pipeline Creation
Data needs have taken multiple leaps with the creation and execution of data pipelines. Partially, because of the need for sophisticated handling methods and partially because data is as big an asset as revenue.
Data pipeline creation can be accomplished with the help of both open source ETL tools and cloud-based tools. The concept of data pipeline creation brought algorithms, data structures, distributed systems, and more into the picture. The process is now customizable.
Big brands are now investing in a full-fledged data strategy for a seamless, smooth transition to simultaneously gather data, process it simultaneously, maintain the database for immediate access and quick resolution in case of assistance during technical glitches, if any, and more.
Have you personally implemented ETL in some form or another? How was your experience? Leave us a comment here.
Dhananjay (DJ) Goel is the CTO at Alphalogic, passionate about technology, startups, game of thrones and coffee. He enjoys working on challenging problems with innovative startups.